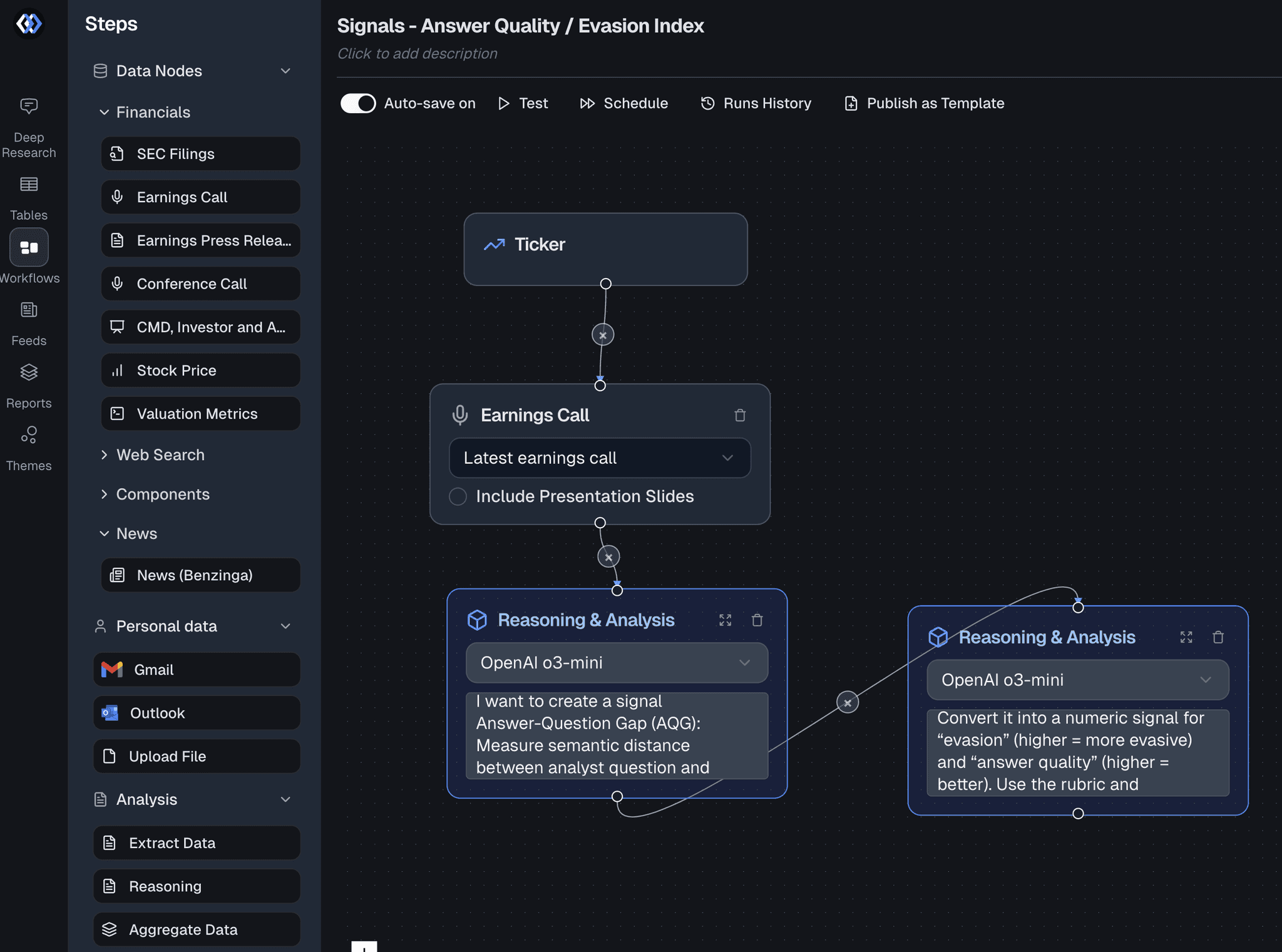
Management evading questions during earnings calls along with declining KPIs: Complete Prompts & Workflow
Implementation workflow
1) Data & preprocessing
Source: earnings call Q&A transcript.
Split the Q&A into exchanges: Analyst question + Management answer(s).
👉 Run a lightweight per-exchange summarizer so the downstream scoring prompt sees concise inputs.
2) Scoring with an LLM (prompt below)
For each exchange, the model assigns:
AnswerQuality_0to10 across five sub-dimensions (directness, completeness, quantification, time specificity, internal consistency).
EvasionSeverity_0to1 and EvasionType (deflection, vagueness, non-answer, delay_to_future_event, selective_answer, inconsistency).
MaterialityWeight_0to2 based on how central the topic is to valuation this quarter.
👉Run a reasoning prompt with best available model on the summarized earnings call. This context engineering is essential to extract the maximum quality deduction from the model.
Roughly the workflow should look like the following (see the prompts down below 🔽):
Matterfact is a finance specific workflow engine that streamlines building signal generation workflows. This above workflow is part of inbuilt signals you can use. Sign up for a free trial at https://app.matterfact.com/auth/sign-up
3) Aggregation (call-level)
Let there be N scored exchanges with valid materiality:
Evasion Index (AQG)
EvasionIndex = 100 × ( Σ(EvasionSeverity_i × Materiality_i) / Σ(Materiality_i) )Answer Quality
AnswerQuality = 10 × ( Σ(AnswerQuality_i × Materiality_i) / Σ(Materiality_i) )Evasion Incidence
evasion_incidence = (# exchanges with EvasionSeverity ≥ 0.5) / NTop evasive topics (max 3) by
(EvasionSeverity × Materiality)with short evidence snippets.
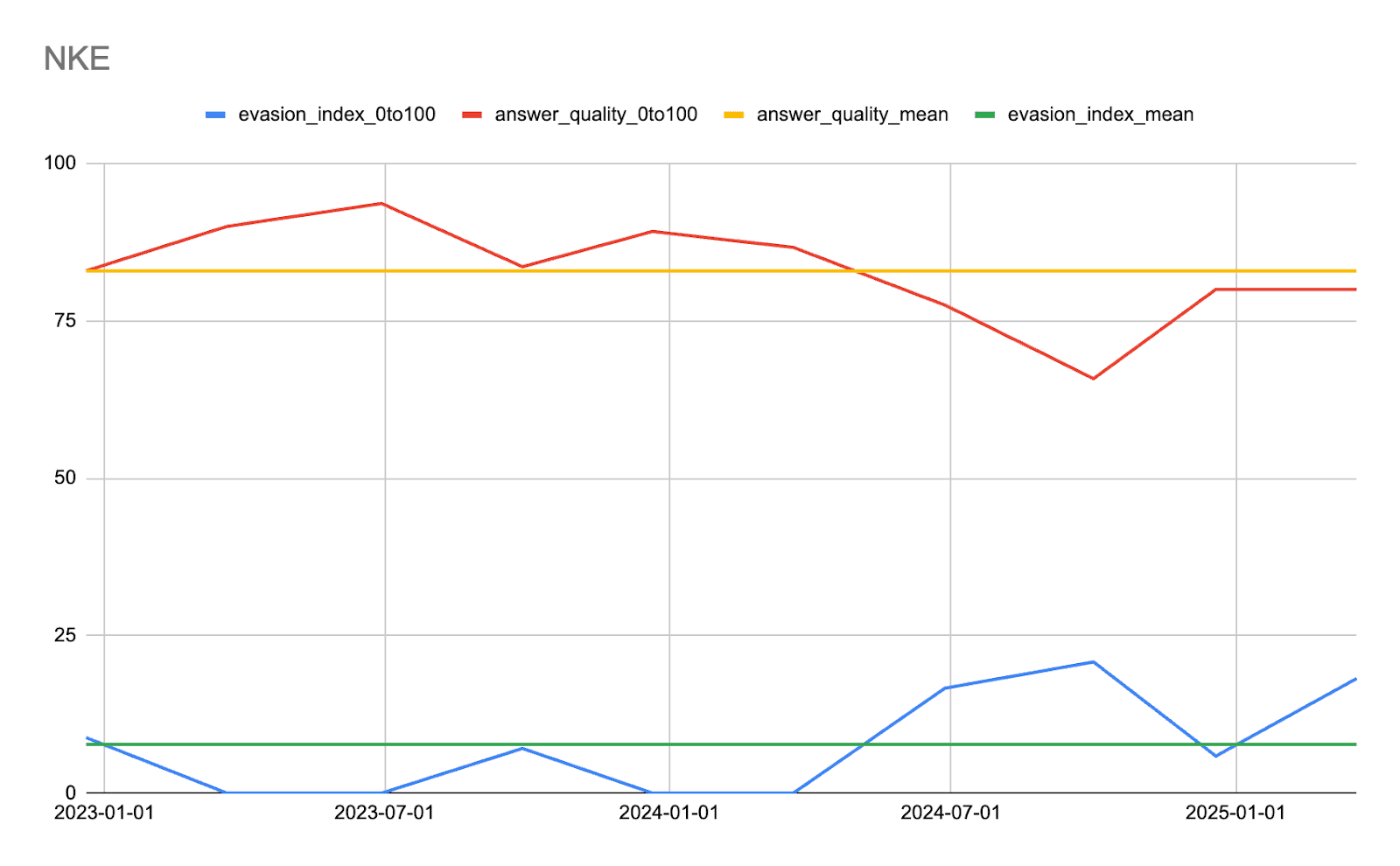
Example Signal Outputs
Nike as a company is increasingly facing issues and management is starting to evade analyst questions. The signal we built is showing signs of increasing evasion by management.
4) Baselines & normalization (critical)
Company baseline: trailing 8 quarters.
Sector baseline: normalize within GICS industry—some sectors and CEOs are systematically vaguer.
Speaker effect: CFO vs. CEO differences—optional fixed effect if you have speaker attribution.
Z-score it:
AQG_z = (AQG − mean_baseline) / std_baseline.Screening rule: flag if
AQG_z ≥ +1.0(≈ top ~16%) or ≥ +20% above company baseline and KPIs/guidance show negative delta.
5) Screening logic
Primary trigger:
AQG_z ≥ +1.0orAQG ≥ baseline × 1.2Confirmatory KPI rule: any of
Guidance cut vs. prior,
Negative KPI delta (e.g., traffic, same-store, order growth),
Adverse mix/margin signals.
Actionable list: top-N names meeting both conditions → push to PMs with top evasive topics snippets.
6) Deploy
Alerts: trigger when
AQG_zcrosses threshold and your KPI rule fires (see next section).
Dashboards: show time series of AQG, Answer Quality, incidence, and top evasive topics with snippets.
Copy-paste prompt (JSON-only output)
Use this prompt on the per-call analysis after you’ve summarized each exchange. The model will return a call-level JSON object plus a by_exchange array you can store for time-series analysis.
|
Pitfalls, and extensions
Pitfalls
Multi-part questions: score evasion only if the key part is dodged.
Legal/quiet periods and pending M&A can inflate AQG; annotate these and down-weight if needed.
Coverage bias: small N exchanges → lower confidence.
Sector style: baseline within sector to avoid penalizing culturally terse management teams.
Extensions
Speaker decomposition (CEO vs. CFO vs. COO).
Audio-only cues (hesitations, non-lexical fillers) as an add-on channel.
Narrative clusters: group evasive topics (pricing, capex, China, promotions) to see what’s getting slippery across a sector.